You can read my review of Phind, another LLM tool, here.
For the past several weeks, I’ve been using Claude Opus (the paid version of Anthropic’s ChatGPT competitor).
For the first time, I think ChatGPT has been outclassed.
For context, I use Claude for help coding (you can read about my process for coding with GPTs here), for understanding new-to-me technical concepts, and for marketing, business, and technical writing.
Here’s what I like about Claude:
It feels smarter. I’m not sure exactly how to quantify this, except to say it’s like when you sync slightly better with one coworker than another. On coding projects, I notice fewer suggestions that lead me down a dead end or that add unnecessary scope.
It has less of a heavy tone on writing. I feel like ChatGPT gives me decent feedback on my writing, but when I ask it to write for me, it feels like it has been written by ChatGPT (some hallmarks: excessive excitement, over explaining). This is fine in some cases, but in others, I end up having to remove the ChatGPT-ness of it.
With that said, Claude has some pretty big limitations:
Just 5 images per chat is a crime. Screenshots of error messages is the default now.
I really miss the context I’ve been able to add to my own customGPT for my coding project. It’s not a lot of extra information, but having the LLM know my basic directory structure saves a lot of extra messages.
If there is a way to stop a message, edit it, and resend it, I haven’t found it yet in ~3 weeks of daily usage.
Despite all these limitations, given the choice between which one to work with, I am consistently choosing Claude. I wonder what this says about the stickiness of these tools?
Now for the ultimate test: have I cancelled my ChatGPT subscription yet?
No, but for an unexpected reason: the ChatGPT mobile app. I’ve been having voice conversations with ChatGPT mobile, both personally when there’s a topic I want to dig into, and increasingly with my daughter. We pick a topic she’s interested in (e.g., where do dinosaurs come from) and just riff on it. It’s perfect for a curious toddler — she can keep asking questions over and over again. I think this is what Tyler Cowen means when he says creators are competing with LLMs for attention.
We’ll see how long this lasts — I don’t expect that I will continue keeping two LLM subscriptions forever. Hurry up and add a mobile app, Claude team!
I found Phind via Marginal Revolution and Tyler Cowen's recommendation. Overall, I found it to be close to ChatGPT 4, if not slightly better — and free!
I decided to try it out because the moment last year when it seemed like OpenAI might implode reminded me again how reliant I am on ChatGPT, especially for programming.
As I've written before, I don't really program. Instead, I scope and test. My typical workflow looks something like this:
Overall project definition: I start by asking ChatGPT: I want to build a search feature for my blog that finds the best posts for a given query. What components would go into that?
Based on what I get back, I ask questions or refine the scope. Frequently there are features I can remove or requirements I've forgotten.
Eventually we end up with a set of components we need to build: A search bar in the UI, a results page, an API that takes the query and searches the database (I don't know what actually goes here, I haven't done this yet).
Building begins. I ask ChatGPT to get very specific: write the API that is going to query my database of blogposts for me. Often in this step I give ChatGPT context from other parts of my app (e.g., here is my database schema).
I then take the code as ChatGPT has written it and begin to test it. If ChatGPT asks me to install a library, I check that it exists and seems legit first, but beyond that, I use the code ChatGPT has given me.
It never works the first time! In the process, I do a lot of debugging with ChatGPT, copying and pasting in error messages and seeing what I get back.
Eventually it works; in the process, 95% or more of the keystrokes in the code have come from ChatGPT.
This morning, I tried doing this with Phind.
In terms of overall quality, I found Phind to be in line with ChatGPT 4. I didn't side by side test it, but in the past I've been able to feel pretty quickly when I'm accidentally working with ChatGPT 3.5. I didn't feel this difference working with Phind; if anything, it seemed to have slightly higher quality results for coding tasks.
Here are some of the things I liked:
They have an extra place where you can add context. I found this to be super useful, especially bringing Phind in to a project that I've already been coding on for sometime.
The model is also willing to ask you for extra context where it might be helpful in a way that seems like it improves my overall performance.
Their model responses are more skimmable than the ChatGPT equivalent. Little things like giving some styling to filenames help me move quickly through what I'm getting back.
When their model searches for contextual data, it's much less intrusive than when ChatGPT does the same thing. Once ChatGPT starts searching the internet, it seems to only focus on what it finds there and the extra time / context often doesn't improve what I get back; in fact, I find myself turning it off. With Phind, I didn't even notice that it was seeking out extra information from places like Stackoverflow at first - it just incorporated it into the results.
So why do I say they haven't quite nailed it? It's not clear to me as a user how I'm supposed to use these various fields. I can tell that they're useful and I'm fine with guessing as I go, but I wish they gave me more of a model for how to help them. It would also be helpful to be able to pin or save context (e.g., my directory structure).
So my final verdict, at least after one morning: Pfind is a credible peer for ChatGPT4 for coding tasks.
If you were a scale believer over the last few years, the progress we’ve been seeing would have just made more sense. There is a story you can tell about how GPT-4’s amazing performance can be explained by some idiom library or lookup table which will never generalize. But that’s a story that none of the skeptics pre-registered.
As for the believers, you have people like Ilya, Dario, Gwern, etc more or less spelling out the slow takeoff we’ve been seeing due to scaling as early as 12 years ago.
It seems pretty clear that some amount of scaling can get us to transformative AI - i.e. if you achieve the irreducible loss on these scaling curves, you’ve made an AI that’s smart enough to automate most cognitive labor (including the labor required to make smarter AIs).
But most things in life are harder than in theory, and many theoretically possible things have just been intractably difficult for some reason or another (fusion power, flying cars, nanotech, etc). If self-play/synthetic data doesn’t work, the models look fucked - you’re never gonna get anywhere near that platonic irreducible loss. Also, the theoretical reason to expect scaling to keep working are murky, and the benchmarks on which scaling seems to lead to better performance have debatable generality.
So my tentative probabilities are: 70%: scaling + algorithmic progress + hardware advances will get us to AGI by 2040. 30%: the skeptic is right - LLMs and anything even roughly in that vein is fucked.
From Dwarkesh Patel. This is the piece that I've been waiting for someone to right. It doesn't matter if he is right, just the thought exercise of thinking through where the bottlenecks might be is really useful.
Ethan Mollick's fantastic One Useful Thing newsletter has an overview of a recent paper he did studying the impact of AI tools on BCG consultants.
One observation in particular stood out to me:
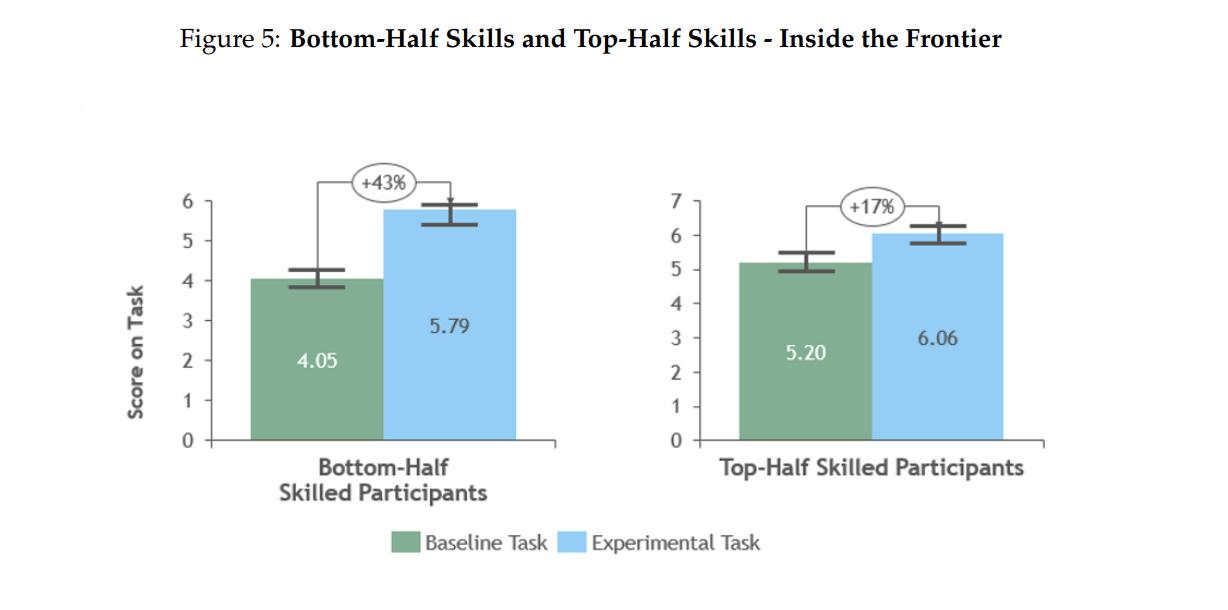
We also found something else interesting, an effect that is increasingly apparent in other studies of AI: it works as a skill leveler. The consultants who scored the worst when we assessed them at the start of the experiment had the biggest jump in their performance, 43%, when they got to use AI. The top consultants still got a boost, but less of one. Looking at these results, I do not think enough people are considering what it means when a technology raises all workers to the top tiers of performance. It may be like how it used to matter whether miners were good or bad at digging through rock… until the steam shovel was invented and now differences in digging ability do not matter anymore. AI is not quite at that level of change, but skill levelling is going to have a big impact.
This data is invaluable, but I think the framing of it (through no fault of the author's) obscures how individuals should be using LLMs. From the perspective of studying the impact of LLMs on a population of BCG consultants, there are low performing consultants and high performing consultants. But as individuals, we are a mix of low performers and high performers depending on the task.
Therefore the implication is that we should be much less afraid of our weaknesses, especially in areas that are complementary to our strengths. The quality (skill?) of being willing to learn by doing is going to be increasingly important, since the LLM will help cover the flaws. Then the way to maximize one's impact is to pick projects where you have a relative strength (beyond the jagged frontier of AI, in Ethan's framing) and pair it with tasks where the LLM can provide complementary, replacement level support.
I can't claim to have mastered this, but over the past 6 months, I've experienced this first hand across a number of domains: programming and in my day job, about material science, chemistry, and technical writing about cosmetics.
My friend Kenneth quipped recently: "What will you do with infinite junior software engineers?", but it's even broader than that. You have infinite access to baseline expertise in basically anything. What will you do with it?